111 lines
6.8 KiB
Markdown
111 lines
6.8 KiB
Markdown
# ClosedParser
|
|
|
|
ClosedParser is a project to parse OOXML grammar to create an abstract syntax tree that can be later evaluated.
|
|
|
|
Official source for the grammar is [MS-XML](https://learn.microsoft.com/en-us/openspecs/office_standards/ms-xlsx/2c5dee00-eff2-4b22-92b6-0738acd4475e), chapter 2.2.2 Formulas. The provided grammar is not usable for parser generators, it's full of ambiguities and the rules don't take into account operator precedence.
|
|
|
|
# How to use
|
|
|
|
* Implement `IAstFactory` interface.
|
|
* Call parsing methods
|
|
* `FormulaParser<TScalarValue, TNode>.CellFormulaA1("Sum(A1, 2)", astFactory)`
|
|
* `FormulaParser<TScalarValue, TNode>.CellFormulaR1C1("Sum(R1C1, 2)", astFactory)`
|
|
|
|
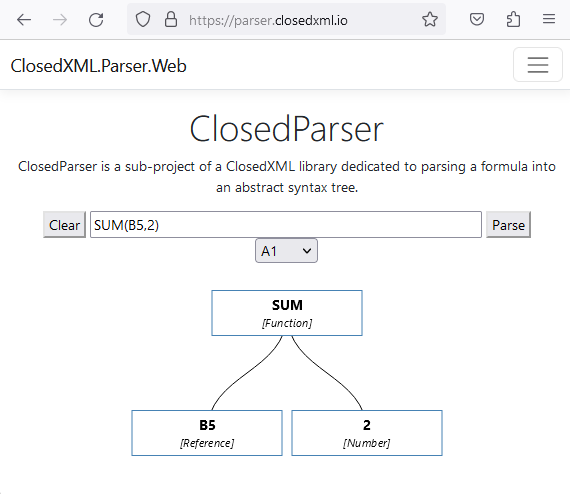
## Visualizer
|
|
There is a visualizer to display AST in a browser at **[https://parser.closedxml.io](https://parser.closedxml.io)**
|
|
|
|
|
|
|
|
# Goals
|
|
|
|
* __Performance__ - ClosedXML needs to parse formula really fast. Limit allocation and so on.
|
|
* __Evaluation oriented__ - Parser should concentrates on creation of abstract syntax trees, not concrete syntax tree. Goal is evaluation of formulas, not transformation.
|
|
* __Multi-use__ - Formulas are mostly used in cells, but there are other places with different grammar rules (e.g. sparklines, data validation)
|
|
* __Multi notation (A1 or R1C1)__ - Parser should be able to parse both A1 and R1C1 formulas. I.e. `SUM(R5)` can mean return sum of cell `R5` in _A1_ notation, but return sum of all cells on row 5 in _R1C1_ notation.
|
|
|
|
Project uses ANTLR4 grammar file as the source of truth and a lexer. There is also ANTLR parser is not used, but is used as a basis of recursive descent parser (ANTLR takes up 8 seconds vs RDS 700ms for parsing of enron dataset).
|
|
|
|
ANTLR4 one of few maintained parser generators with C# target.
|
|
|
|
The project has a low priority, XLParser mostly works, but in the long term, replacement is likely.
|
|
|
|
## Current performance
|
|
|
|
ENRON dataset parsed using recursive descent parser and DFA lexer in Release mode:
|
|
|
|
* Total: *946320*
|
|
* Elapsed: *1838 ms*
|
|
* Per formula: *1.942 μs*
|
|
|
|
2μs per formula should be something like 6000 instructions (under unrealistic assumption 1 instruction per 1 Hz), so basically fast enough.
|
|
|
|
## Limitations
|
|
|
|
The primary goal is to parse formulas stored in file, not user supplied formulas. The formulas displayed in the GUI is not the same as formula stored in the file. Several examples:
|
|
* The IFS function is a part of future functions. In the file, it is stored as `_xlfn.IFS`, but user sees `IFS`
|
|
* In the structured references, user sees @ as an indication that structured references this row, but in reality it is a specifier `[#This Row]`
|
|
|
|
Therefore:
|
|
* External references are accepted only in form of an index to an external file (e.g. `[5]`)
|
|
* There are several formula implementations out there with slighly different grammar incompatible with OOXML formulas (`[1]!'Some name in external wb'`). They are out of scope of the project.
|
|
|
|
# Why not use XLParser
|
|
|
|
ClosedXML is currently using [XLParser](https://github.com/spreadsheetlab/XLParser) and transforming the concrete syntax tree to abstract syntax tree.
|
|
|
|
* Speed:
|
|
* Grammar extensively uses regexps extensively. Regexs are slow, especially for NET4x target, allocates extra memory. XLParser takes up _47_ seconds for Enron dataset on .NET Framework. .NET teams had made massive improvements on regexs, so it takes only _16_ seconds on NET7.
|
|
* IronParser needs to determine all possible tokens after every token, that is problematic, even with the help of `prefix` hints.
|
|
* AST: XLParser creates concentrates on creation of concrete syntax tree, but for ClosedXML, we need abstract syntax tree for evaluation. IronParser is not very friendly in that regard
|
|
* ~~XLParser uses `IronParser`, an unmaintained project~~ (IronParser recently released version 1.2).
|
|
* Doesn't have support for lambdas and R1C1 style.
|
|
|
|
ANTLR lexer takes up about 3.2 seconds for Enron dataset. With ANTLR parsing, it takes up 11 seconds. I want that 7+ seconds in performance and no allocation, so RDS that takes up 700 ms.
|
|
|
|
## Debugging
|
|
|
|
Use [vscode-antlr4](https://github.com/mike-lischke/vscode-antlr4/blob/master/doc/grammar-debugging.md) plugin for debugging the grammar.
|
|
|
|
## Testing strategy
|
|
|
|
* Each token that contains some data that are extracted for a node (e.g. `A1_REFERENCE` `C5` to `row 5`, `column 3`) has a separate test class in `Lexers` directory with a `{TokenPascalName}TokenTests.cs`
|
|
* Each parser rule has a test class in `Rules` directory. It should contain all possible combinatins of a rule and comparing it with the AST nodes.
|
|
* Data set tests are in `DataSetTests.cs`. Each test tries to parse formula and ensures that **ANTLR** can parse it RDS can and can't parse a formula when **ANTLR** can't. There is no check of the output, just that formulas can be parsed. Data are contained in a `data` directory in CSV format with a one column.
|
|
|
|
## Rolex
|
|
|
|
Rolex is a DFA based lexer released under MIT license (see [Rolex: Unicode Enabled Lexer Generator in C#
|
|
](https://www.codeproject.com/Articles/5257489/Rolex-Unicode-Enabled-Lexer-Generator-in-Csharp)). ANTLR is still the source of truth, but it is used to generate Rolex grammar and then DFA for a lexer.
|
|
|
|
It is rather complicated, but two times faster than ANTLR lexer (1.9 us vs 3.676 us per formula).
|
|
|
|
## Generate lexer
|
|
|
|
Prepare rolex grammars
|
|
* Run Antlr2Rolex over FormulaLexer.g4 with A1 version to *ClosedXML.Parser\Rolex\LexerA1.rl*
|
|
* Add `/*` at the beginning of *Local A1 References* section. It comments out A1_REFERENCE and all its fragments
|
|
* Remove `/*` at the beinning of *Local R1C1 References* section. It contains a different tokens for A1_REFERENCE and its fragments
|
|
* Run Antlr2Rolex over FormulaLexer.g4 with R1C1 version to *ClosedXML.Parser\Rolex\LexerR1C1.rl*
|
|
|
|
Fix Rolex generator
|
|
* Fix bug in Rolex generator that doesn't recognize property \u1234 (just add `pc.Advance()` to FFA.cs `_ParseEscapePart` and `_ParseRangeEscapePart`]
|
|
|
|
Generate a DFA through Rolex
|
|
* `Rolex.exe ClosedXML.Parser\Rolex\LexerA1.rl /noshared /output ClosedXML.Parser\Rolex\RolexA1Dfa.cs /namespace ClosedXML.Parser.Rolex`
|
|
* `Rolex.exe ClosedXML.Parser\Rolex\LexerR1C1.rl /noshared /output ClosedXML.Parser\Rolex\RolexR1C1Dfa.cs /namespace ClosedXML.Parser.Rolex`
|
|
|
|
# TODO
|
|
|
|
* Lexer generation during build
|
|
* Proper CI pipeline.
|
|
* Azure Function
|
|
* Web
|
|
* Fuzzer
|
|
* PR to Rolex to fix unicode bug.
|
|
|
|
# Resources
|
|
|
|
* [MS-XML](https://learn.microsoft.com/en-us/openspecs/office_standards/ms-xlsx/2c5dee00-eff2-4b22-92b6-0738acd4475e)
|
|
* [Simplified XLParser grammar](https://github.com/spreadsheetlab/XLParser/blob/master/doc/ebnf.pdf) and [tokens](https://github.com/spreadsheetlab/XLParser/blob/master/doc/tokens.pdf).
|
|
* [Getting Started With ANTLR in C#](https://tomassetti.me/getting-started-with-antlr-in-csharp/)
|